MaxCompute湖倉一體近實(shí)時(shí)增量處理技術(shù)架構(gòu)揭秘
隨著大數(shù)據(jù)和云計(jì)算技術(shù)的快速發(fā)展,企業(yè)數(shù)據(jù)處理需求日益復(fù)雜,對(duì)數(shù)據(jù)處理的時(shí)效性、靈活性和成本效益提出了更高要求。阿里云MaxCompute作為領(lǐng)先的數(shù)據(jù)處理平臺(tái),結(jié)合湖倉一體(Lakehouse)架構(gòu),推出了近實(shí)時(shí)增量處理技術(shù),為企業(yè)數(shù)據(jù)處理服務(wù)帶來了革命性的提升。本文將從技術(shù)架構(gòu)、核心組件與數(shù)據(jù)處理流程三個(gè)方面,深入揭秘MaxCompute湖倉一體的近實(shí)時(shí)增量處理技術(shù)。
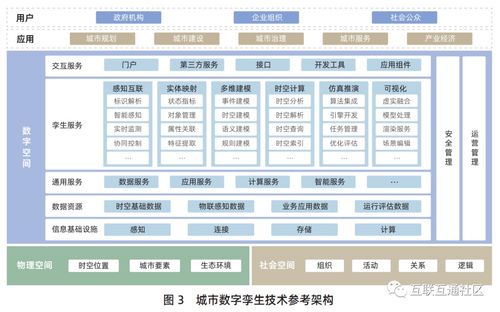
一、技術(shù)架構(gòu)概述
MaxCompute湖倉一體架構(gòu)融合了數(shù)據(jù)湖的靈活性和數(shù)據(jù)倉庫的高性能,支持結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)的統(tǒng)一存儲(chǔ)與處理。近實(shí)時(shí)增量處理技術(shù)是該架構(gòu)的核心之一,它通過流批一體、增量更新和事務(wù)一致性機(jī)制,實(shí)現(xiàn)了數(shù)據(jù)從產(chǎn)生到分析的低延遲處理。架構(gòu)主要包括數(shù)據(jù)源層、接入層、存儲(chǔ)層、計(jì)算層和服務(wù)層:
- 數(shù)據(jù)源層:支持多種數(shù)據(jù)源,如數(shù)據(jù)庫日志、IoT設(shè)備、應(yīng)用程序事件等,通過CDC(Change Data Capture)或消息隊(duì)列(如Kafka)實(shí)時(shí)捕獲增量數(shù)據(jù)。
- 接入層:采用MaxCompute Tunnel或DataHub服務(wù),實(shí)現(xiàn)數(shù)據(jù)的快速接入和緩沖,確保數(shù)據(jù)高效流入存儲(chǔ)層。
- 存儲(chǔ)層:基于對(duì)象存儲(chǔ)(如OSS)構(gòu)建統(tǒng)一數(shù)據(jù)湖,同時(shí)利用MaxCompute的表存儲(chǔ)格式(如ORC、Parquet)優(yōu)化數(shù)據(jù)組織,支持ACID事務(wù)和增量快照。
- 計(jì)算層:通過MaxCompute SQL、Spark或Flink引擎,實(shí)現(xiàn)流批混合計(jì)算,自動(dòng)處理增量數(shù)據(jù),并提供近實(shí)時(shí)查詢能力。
- 服務(wù)層:為上層應(yīng)用提供數(shù)據(jù)API、數(shù)據(jù)服務(wù)和可視化工具,支持實(shí)時(shí)報(bào)表、機(jī)器學(xué)習(xí)和業(yè)務(wù)分析。
二、核心組件與技術(shù)特點(diǎn)
MaxCompute近實(shí)時(shí)增量處理技術(shù)的成功依賴于多個(gè)核心組件:
- 增量數(shù)據(jù)捕獲:使用Debezium或自定義CDC工具,從源系統(tǒng)捕獲數(shù)據(jù)變更事件,確保數(shù)據(jù)完整性和低延遲。
- 流式處理引擎:集成Flink或Spark Streaming,處理實(shí)時(shí)數(shù)據(jù)流,支持窗口計(jì)算、狀態(tài)管理和容錯(cuò)機(jī)制。
- 統(tǒng)一元數(shù)據(jù)管理:通過Hive Metastore或MaxCompute內(nèi)置元數(shù)據(jù)服務(wù),實(shí)現(xiàn)數(shù)據(jù)湖和倉庫的元數(shù)據(jù)一致性,簡化數(shù)據(jù)發(fā)現(xiàn)和治理。
- 增量合并與優(yōu)化:采用Delta Lake或Iceberg等開源表格式,支持增量數(shù)據(jù)的合并、壓縮和版本控制,減少存儲(chǔ)冗余并提升查詢性能。
- 事務(wù)保障:基于多版本并發(fā)控制(MVCC)和快照隔離,確保在并發(fā)場景下數(shù)據(jù)的一致性和可靠性。
技術(shù)特點(diǎn)包括:
- 近實(shí)時(shí)處理:數(shù)據(jù)從產(chǎn)生到可查詢的延遲可控制在分鐘級(jí),滿足業(yè)務(wù)對(duì)時(shí)效性的需求。
- 成本效益:通過增量處理減少全量計(jì)算,降低資源消耗和成本。
- 靈活性:支持多種數(shù)據(jù)格式和計(jì)算引擎,便于企業(yè)根據(jù)場景選擇最佳方案。
- 易用性:提供SQL接口和可視化工具,降低開發(fā)門檻,提升數(shù)據(jù)處理效率。
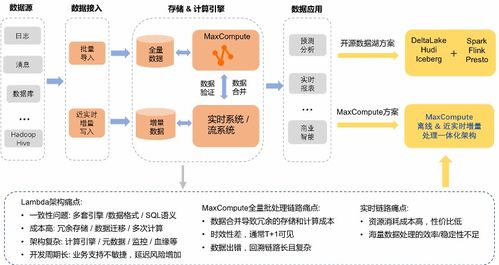
三、數(shù)據(jù)處理流程與實(shí)戰(zhàn)應(yīng)用
在實(shí)際應(yīng)用中,MaxCompute湖倉一體的近實(shí)時(shí)增量處理技術(shù)廣泛應(yīng)用于電商、金融、物聯(lián)網(wǎng)等領(lǐng)域。典型數(shù)據(jù)處理流程如下:
- 數(shù)據(jù)采集:從業(yè)務(wù)數(shù)據(jù)庫(如MySQL)通過CDC工具捕獲增量數(shù)據(jù),并發(fā)送到消息隊(duì)列。
- 數(shù)據(jù)接入:使用DataHub或Tunnel服務(wù)將數(shù)據(jù)接入MaxCompute存儲(chǔ)層,存儲(chǔ)在數(shù)據(jù)湖中。
- 增量計(jì)算:通過Flink作業(yè)處理實(shí)時(shí)數(shù)據(jù)流,進(jìn)行數(shù)據(jù)清洗、轉(zhuǎn)換和聚合,結(jié)果寫入增量表。
- 數(shù)據(jù)服務(wù):利用MaxCompute的查詢引擎,提供近實(shí)時(shí)數(shù)據(jù)分析,并通過DataWorks或Quick BI等服務(wù)輸出結(jié)果。
例如,在電商場景中,該技術(shù)可用于實(shí)時(shí)更新用戶行為數(shù)據(jù),支持個(gè)性化推薦和庫存監(jiān)控。通過增量處理,企業(yè)能夠快速響應(yīng)市場變化,提升業(yè)務(wù)敏捷性。
MaxCompute湖倉一體的近實(shí)時(shí)增量處理技術(shù)通過創(chuàng)新的架構(gòu)設(shè)計(jì)和核心組件,實(shí)現(xiàn)了數(shù)據(jù)處理的高效、實(shí)時(shí)和統(tǒng)一。它不僅降低了數(shù)據(jù)管理的復(fù)雜性,還為企業(yè)提供了強(qiáng)大的數(shù)據(jù)處理服務(wù),助力數(shù)字化轉(zhuǎn)型。隨著AI和邊緣計(jì)算的融合,這一技術(shù)將進(jìn)一步演進(jìn),滿足更廣泛的數(shù)據(jù)處理需求。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.tomck.cn/product/20.html
更新時(shí)間:2026-01-23 15:31:48