嗶哩嗶哩數(shù)據(jù)服務(wù)中臺建設(shè)實踐 數(shù)據(jù)處理服務(wù)的架構(gòu)與挑戰(zhàn)
在嗶哩嗶哩(Bilibili)這一龐大的數(shù)字內(nèi)容生態(tài)中,數(shù)據(jù)是驅(qū)動業(yè)務(wù)增長、優(yōu)化用戶體驗和實現(xiàn)精細(xì)化運營的核心燃料。為了高效、穩(wěn)定地管理海量、多元的數(shù)據(jù)流,嗶哩嗶哩構(gòu)建了先進的數(shù)據(jù)服務(wù)中臺,其中數(shù)據(jù)處理服務(wù)作為關(guān)鍵一環(huán),扮演著數(shù)據(jù)“心臟”的角色。本文將探討嗶哩嗶哩在數(shù)據(jù)處理服務(wù)中臺建設(shè)方面的實踐與思考。
一、數(shù)據(jù)處理服務(wù)的核心定位與挑戰(zhàn)
嗶哩嗶哩的數(shù)據(jù)處理服務(wù)位于數(shù)據(jù)中臺的核心層,其主要職責(zé)是承接來自各業(yè)務(wù)線(如視頻點播、直播、社區(qū)互動、電商等)的原始數(shù)據(jù),經(jīng)過清洗、轉(zhuǎn)換、聚合、計算等一系列加工流程,最終產(chǎn)出可供下游分析、應(yīng)用、算法模型使用的標(biāo)準(zhǔn)化數(shù)據(jù)資產(chǎn)。其面臨的挑戰(zhàn)包括:
- 數(shù)據(jù)規(guī)模巨大:每日需處理PB級別的用戶行為、視頻播放、彈幕評論等數(shù)據(jù)。
- 實時性要求高:如推薦系統(tǒng)、風(fēng)控監(jiān)控等場景需要秒級甚至毫秒級的實時數(shù)據(jù)處理能力。
- 數(shù)據(jù)多樣性:結(jié)構(gòu)化、半結(jié)構(gòu)化(如JSON日志)、非結(jié)構(gòu)化(如圖片、音頻元數(shù)據(jù))數(shù)據(jù)并存。
- 業(yè)務(wù)快速迭代:新業(yè)務(wù)、新功能層出不窮,數(shù)據(jù)處理流程需要靈活、可擴展。
二、架構(gòu)設(shè)計與關(guān)鍵技術(shù)棧
嗶哩嗶哩的數(shù)據(jù)處理服務(wù)采用了分層、流批一體的混合架構(gòu):
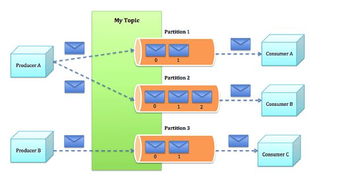
- 數(shù)據(jù)采集與接入層:通過自研的Agent、Logstash、Flume等工具,從業(yè)務(wù)服務(wù)器、客戶端、第三方服務(wù)等源頭實時/離線采集數(shù)據(jù),并統(tǒng)一寫入Kafka消息隊列,作為數(shù)據(jù)總線。
- 實時計算層:基于Apache Flink構(gòu)建實時計算引擎。Flink的高吞吐、低延遲特性完美支撐了實時指標(biāo)計算(如在線人數(shù)、熱門視頻)、實時用戶畫像更新、實時異常檢測等場景。通過Flink SQL和自定義UDF,開發(fā)效率大幅提升。
- 批量計算層:基于Apache Spark和Hive構(gòu)建離線計算體系。負(fù)責(zé)T+1的批量ETL任務(wù)、歷史數(shù)據(jù)回溯、復(fù)雜報表生成等。通過YARN或Kubernetes進行資源調(diào)度,確保集群資源高效利用。
- 數(shù)據(jù)存儲層:根據(jù)數(shù)據(jù)特性和訪問模式,選用不同的存儲方案:
- 實時明細(xì)數(shù)據(jù):存入Apache Druid或ClickHouse,支持高性能OLAP查詢。
- 批量結(jié)果數(shù)據(jù):存入HDFS,并通過Hive Metastore進行元數(shù)據(jù)管理。
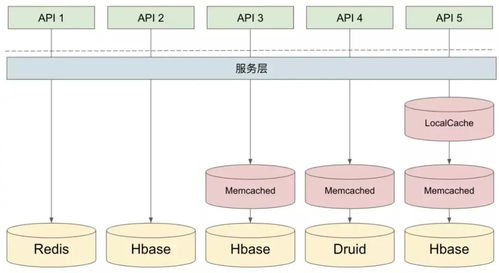
- 維度數(shù)據(jù)與中間結(jié)果:使用MySQL、Redis或HBase。
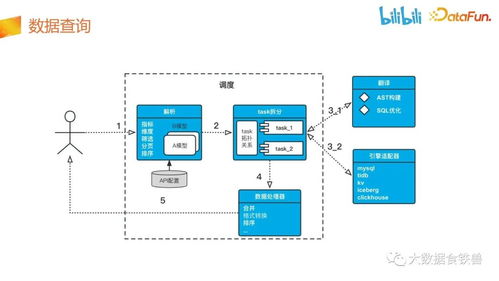
- 任務(wù)調(diào)度與運維層:采用Airflow或自研調(diào)度平臺,管理復(fù)雜的依賴關(guān)系與定時任務(wù)。建設(shè)了完善的監(jiān)控告警體系(如Prometheus+Grafana),對任務(wù)健康度、數(shù)據(jù)質(zhì)量、資源使用率進行全方位監(jiān)控。
三、核心實踐與優(yōu)化
- 數(shù)據(jù)標(biāo)準(zhǔn)化與模型建設(shè):推行統(tǒng)一的數(shù)據(jù)規(guī)范(如OneData模型),建立主題域、業(yè)務(wù)過程、維度與事實表模型,減少數(shù)據(jù)冗余與歧義,提升數(shù)據(jù)一致性。
- 流批一體與Lambda架構(gòu)演進:積極探索流批融合,如在Flink中實現(xiàn)同一套邏輯同時處理實時流和歷史數(shù)據(jù),簡化架構(gòu),降低維護成本。
- 數(shù)據(jù)質(zhì)量保障:建立數(shù)據(jù)血緣追蹤、數(shù)據(jù)稽核(如總量、唯一性、波動性校驗)、故障熔斷與數(shù)據(jù)回溯機制,確保數(shù)據(jù)處理結(jié)果的準(zhǔn)確性與可靠性。
- 資源優(yōu)化與成本控制:通過動態(tài)資源調(diào)整(如Flink Reactive Mode)、計算存儲分離、冷熱數(shù)據(jù)分級存儲、作業(yè)參數(shù)調(diào)優(yōu)等手段,在保障SLA的同時有效控制計算與存儲成本。
- 平臺化與自助服務(wù):將數(shù)據(jù)處理能力封裝成標(biāo)準(zhǔn)化的數(shù)據(jù)開發(fā)平臺(DataWorks),提供可視化的ETL開發(fā)、任務(wù)調(diào)試、運維監(jiān)控界面,賦能業(yè)務(wù)團隊和數(shù)據(jù)分析師自助進行數(shù)據(jù)開發(fā),提升整體效率。
四、價值與未來展望
通過構(gòu)建強大的數(shù)據(jù)處理服務(wù)中臺,嗶哩嗶哩實現(xiàn)了:
- 效率提升:數(shù)據(jù)開發(fā)周期從“天”縮短到“小時”,快速響應(yīng)業(yè)務(wù)需求。
- 質(zhì)量可靠:數(shù)據(jù)準(zhǔn)確性、時效性得到保障,為決策提供可信依據(jù)。
- 成本優(yōu)化:資源利用率提高,基礎(chǔ)設(shè)施成本得到有效控制。
- 創(chuàng)新賦能:為A/B測試、個性化推薦、智能運營等高級應(yīng)用提供了堅實的數(shù)據(jù)基石。
嗶哩嗶哩的數(shù)據(jù)處理服務(wù)將繼續(xù)向更智能化、更自動化的方向演進,例如利用機器學(xué)習(xí)優(yōu)化任務(wù)調(diào)度與資源配置,深化實時計算能力以支持更復(fù)雜的實時業(yè)務(wù)場景,并進一步擁抱云原生技術(shù),提升系統(tǒng)的彈性與可觀測性,持續(xù)支撐嗶哩嗶哩生態(tài)的繁榮發(fā)展。
如若轉(zhuǎn)載,請注明出處:http://www.tomck.cn/product/45.html
更新時間:2026-01-23 12:36:55